How does it work?
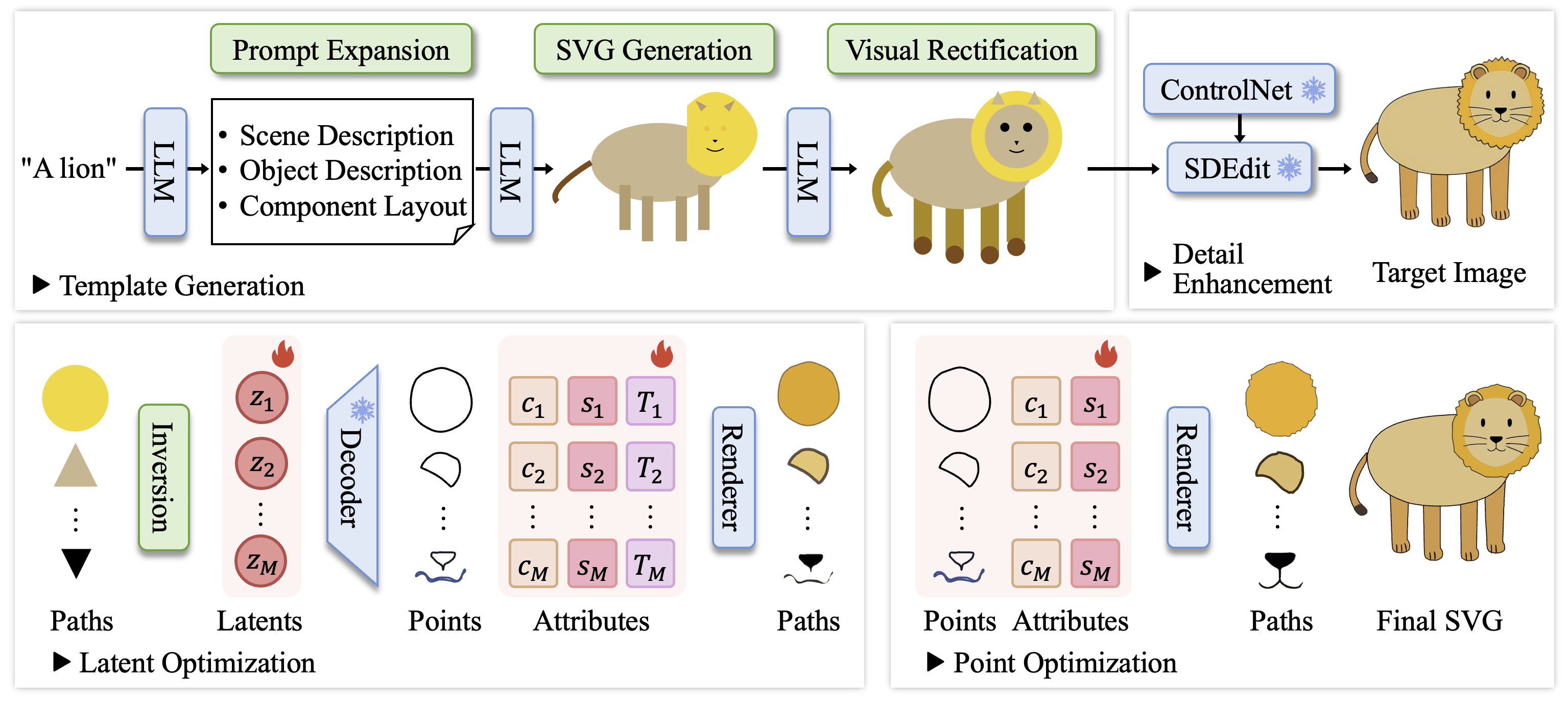
Given a text prompt, our system first leverages an LLM to generate an SVG template composed of basic geometric primitives. The rendered template is enhanced through SDEdit with ControlNet to add visual details while preserving the overall composition, yielding a target image. The SVG then undergoes a dual-stage optimization process to match the target image.
(1) Primitives are converted to latent embeddings through latent inversion and optimized along with their visual attributes (i.e., filling colors ci, stroke properties si, and transformation matrices Ti).
(2) Point-level optimization is performed to refine the geometric details of SVG paths.
(1) Primitives are converted to latent embeddings through latent inversion and optimized along with their visual attributes (i.e., filling colors ci, stroke properties si, and transformation matrices Ti).
(2) Point-level optimization is performed to refine the geometric details of SVG paths.
Text-Guided SVG Generation

SVG examples generated by our Chat2SVG. We highlight some shapes to demonstrate semantic clarity and path quality.
Text-Guided SVG Editing
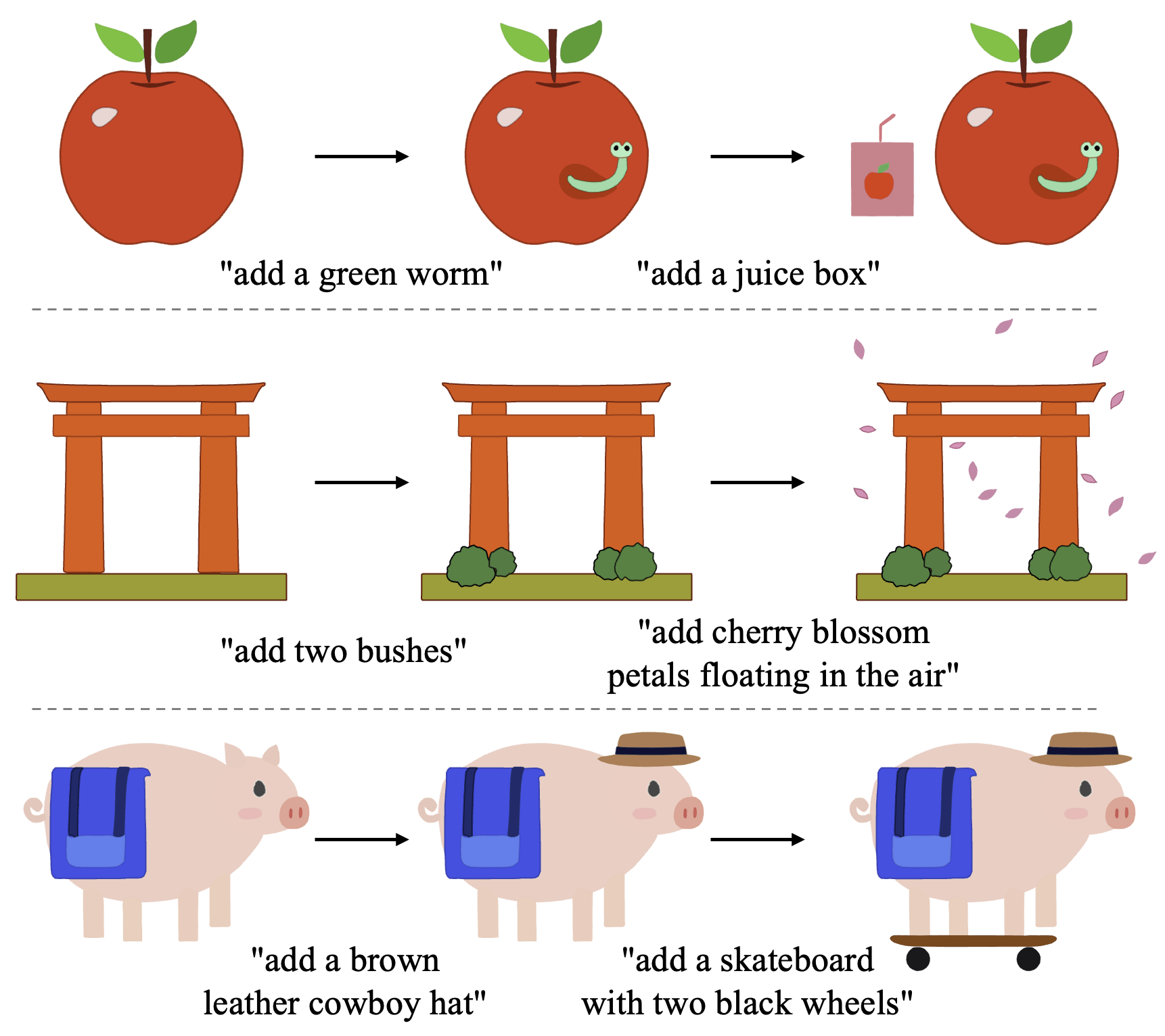
We perform two rounds of refinement on each SVG template and show the optimized output.
This figure shows editing types including deletion, modification, and addition.